이 포스트는 PC 환경에서 작성되었습니다.
스마트폰과 태블릿 등의 모바일 환경에 최적화되어있지 되지 않을 수 있다는 점을 알려드리며, 가급적 PC에서 조회해 주시길 부탁드립니다.
안녕하세요, 레이븐입니다.
여러분들은 그래픽 카드하면 어느 회사를 떠올리시나요?
많은 분들이 부동의 1위, 엔비디아를 떠올리시는 경우가 많을 것입니다.
특히 RTX 30 시리즈가 엄청난 성능 향상과 동시에 엄청난 가격 향상까지 이룬데다 그마저도 매물이 없어 구하지 못하는 상황이죠. (그놈의 채굴 공장들....)
하지만 저는 예전부터 ATi 시절부터 이어져오는 AMD 그래픽 카드를 애용하곤 했습니다.
심지어 남들은 실패작이라고 하는 VEGA 64 모델을 커스텀 수랭까지 해가며 쓰고 있죠... 이젠 수랭 블럭도 못 구합니다.
AMD 그래픽 카드는 그간 엔비디아에 비해 떨어지는 성능과 전성비, 출시 초기에 항상 잦은 오류와 잔고장 문제로 대중 시장에 외면을 받아왔습니다.
하지만 지난 RDNA 2 아키텍쳐, 즉 RX 6000번대 시리즈에서 약간의(진짜 약간의...) 전성비 개선, RTX 30 시리즈와 비교해도 손색 없을 정도의 높은 성능 개선, 그리고 제법 경쟁력 있는 가격 책정 덕에 많은 소비자들의 인식을 개선할 수 있는 기회가 되었습니다.
그래봤자 RX 6000번대 역시 채굴 공장으로 모두 끌려가 구경도 하기 어려운 지경이 되었지만요.
각설하고, 지난 27일 Hardware Times를 통해 AMD의 차세대 그래픽 아키텍쳐인 RDNA 3의 Navi 31(RX 7900XT로 추정) 블록 다이어그램으로 추정되는 정보들이 공개되었습니다. (오피셜은 아님)
해당 칼럼에 따르면 RDNA 2에서 많은 구조적 변경이 있을 것으로 보이며, 특히 프론트엔드 설계에 있어 더이상 컴퓨트 유닛(CU)을 사용하지 않고 '워크 그룹 프로세서(WGP)'를 사용하는 것으로 추정됩니다.
애당초 RX 6000번대, 즉 RDNA 2 아키텍쳐는 나올 예정이 없었으나 개발진의 요청으로 추진된 사업으로 알고 있기에 RDNA 3는 성능 개선 버전 정도로 생각했었는데, 큰 구조적 변화가 예상된다니 의외입니다.
Here's a Look at AMD's Radeon RX 7900 XT (Navi 31) Purported Block Diagram w/ 256 Core WGPs Instead of CUs | Hardware Times
AMD’s RDNA 3 graphics architecture is expected to get a major design change on the front-end, with redesigned Work Group Processors and no Compute Units, or Dual Compute Units for that matter. With RDNA 1 and 2, the WGPs were the basic units for workload
www.hardwaretimes.com
기존 GCN-VEGA 아키텍쳐에서는 CU를 사용하던 것과 달리, WGP는 이미 RDNA 1 및 RDNA 2에서도 워크로드 스케쥴링의 기본 단위로 사용되던 방식이긴 합니다만 RDNA 3에서 다시금 많은 수정을 거칠 것으로 보입니다.
특히 RDNA 2까지도 사용되었던 듀얼 컴퓨트 유닛(DCU) 방식은 보다 대역폭이 넓은 WGP를 적용하면서 폐기될 예졍이라고 하며, WGP의 구조는 8개의 32-와이드 SIMD를 거치는 총 256 스트림 프로세서 방식인 것으로 추정됩니다.

공개된 Navi 31의 아키텍쳐 이미지를 살펴보자면 우선 2개의 GCD(그래픽다이)를 512MB의 MCD(L3 infinity 캐시 메모리)를 통해 브릿지로 상호 연결되는 방식입니다.
각각의 GCD에는 3개의 셰이더 엔진이 할당되며, 각 셰이더 엔진에는 2개의 셰이더 어레이가 할당되는 방식입니다.
즉 하나의 그래픽 다이에 6개의 셰이더 어레이가 할당되는 방식입니다.
각각의 셰이더 어레이에는 총 5개의 WGP가 할당되며(RDNA 2는 4개), 하나의 WGP는 8개의 SIMD 장치를 포함합니다.
Hardware Times에 따르면 그래픽 다이는 TSMC의 5nm 공정, MCD는 6nm 공정을 적용한다고 합니다만, 보통 '소식통에 따르면'이라는 식의 정보는 확실하지 않으니 그냥 참고만 하시면 되겠습니다.
각 그래픽 다이는 128-bit 버스를 8개의 컨트롤러로 분할 적용하는 방식으로, 외부 대역폭은 448GB/s, 전체 버스는 256-bit로 RX 6800XT, RX 6900XT와 동일한 대역폭으로 예상됩니다.
해당 블록 다이어그램대로라면 256 스트림 프로세서의 WGP가 60개 적용되는 방식이니 총 15,360 스트림 프로세서가 적용되는 방식이며 CU나 DCU를 쓸 때보다 훨씬 집적도가 높아진 셈입니다.
처음 RX 6800XT 공개 당시 256비트 적용에 대해 이걸 누구 코에 붙이냐는 여론이 강했으나, 막상 성능이 공개되었을 때는 획기적인 구조 개선으로 높은 효율을 뽑았던 것을 감안하면 RDNA 3도 기대해볼 만한 구조 변경이지 않을까 싶습니다.
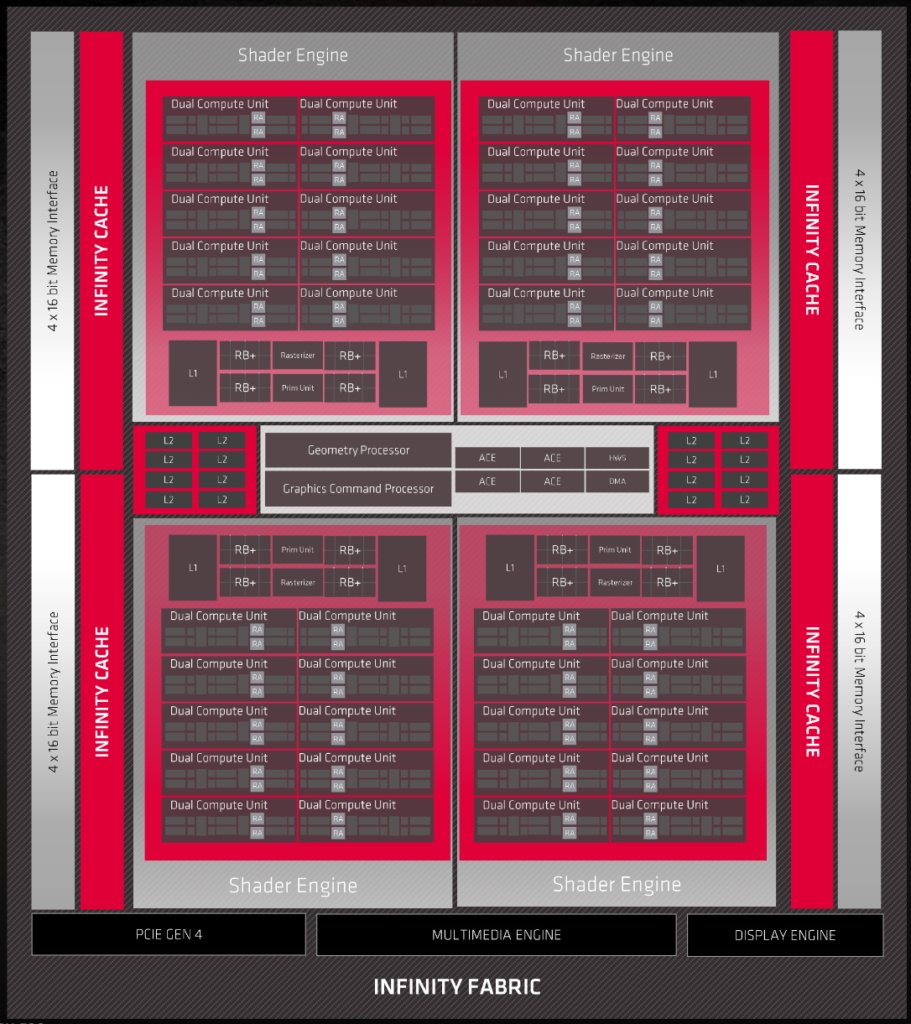
비교 대상인 Navi 21은 10개의 DCU, 즉 20개의 CU를 묶은 셰이더 엔진이 총 4개 적용되는 방식입니다.
각 CU는 2개의 SIMD로 분할되며, CU마다 텍스처 맵핑 유닛, 레지스터 및 캐시, 벡터·스칼라 유닛이 할당됩니다.
스케쥴링은 DCU 단위의 WGP를 기반으로 이루어지며, 한 번에 4개의 wave32 워크그룹이 할당되는 방식입니다.
Navi 31이 8개의 SIMD를 거치며 8개의 wave32 워크그룹을 한 번에 적용하는 방식이기 때문에 스케쥴링은 더욱 복잡해지지만, 동시에 집적도와 아키텍처의 효율 개선은 더욱 발전했음을 확인해볼 수 있는 정보였습니다.

이대로만 나와준다면 안 그래도 호평을 받았던 RX 6900XT에서 보다 발전한 플래그십 그래픽 카드를 AMD에서 만나볼 수 있을 것으로 보입니다.
현재 채굴 프로그램 블록 문제 등으로 계속 골머리를 썩고 있는 엔비디아에서 특별한 혁신과 신기술 개발을 보여주지 않는 한 내년 후반기쯤 공개될 RX 7900XT가 엔비디아 플래그십 그래픽 카드를 성능으로 앞서는 모습도 볼 수 있게 되지 않을까 기대해봅니다.
제발... 가격과 물량 공급만 좀 어떻게 접근성 있는 영역으로 형성되었으면 좋겠습니다만...

마지막까지 읽어주셔서 감사드리며, 재미있게 읽으셨다면 ♥공감과 구독 부탁드립니다.
포스트 내용에 대한 의견이 있으시면 댓글을 부탁드립니다.
또한 좌측 하단의 공유 기능을 이용해 SNS로 이 글을 공유하실 수 있습니다.
'IT & Tech > Device' 카테고리의 다른 글
| [루머] NVIDIA 플래그십 GPU RTX 3090 SUPER 연내로 출시?! (0) | 2021.08.27 |
|---|---|
| ASUS, AM4용 플래그십 마더보드 'ROG Crosshair Ⅷ Extreme' 출시 (0) | 2021.08.19 |
| 누수와 폭☆8?! ㅠㅠ 레이븐의 커스텀 수랭 PC 소생기 (feat. PSIONIC) (1) | 2021.08.14 |
| AMD의 AM5 소켓, LGA 방식 적용된 예상 렌더링 유출 (1) | 2021.07.30 |
| 리사 수 박사, "AMD Zen4와 RDNA3는 2022년 출시될 것" (1) | 2021.07.29 |



